
AI Training Is Outpacing Moore’s Law
The days and sometimes weeks it took to train AIs only a few years ago was a big reason behind the launch of billions of dollars-worth of new computing startups over the last few years—including Cerebras Systems, Graphcore, Habana Labs, and SambaNova Systems. In addition, Google, Intel, Nvidia and other established companies made their own similar amounts of internal investment (and sometimes acquisition). With the newest edition of the MLPerf training benchmark results, there’s clear evidence that the money was worth it.
The gains to AI training performance since MLPerf benchmarks began “managed to dramatically outstrip Moore’s Law,” says David Kanter, executive director of the MLPerf parent organization MLCommons. The increase in transistor density would account for a little more than doubling of performance between the early version of the MLPerf benchmarks and those from June 2021. But improvements to software as well as processor and computer architecture produced a 6.8-11-fold speedup for the best benchmark results. In the newest tests, called version 1.1, the best results improved by up to 2.3 times over those from June.
According to Nvidia the performance of systems using A100 GPUs has increased more than 5-fold in the last 18 months and 20-fold since the first MLPerf benchmarks three years ago.
For the first time Microsoft entered its Azure cloud AI offerings into MLPerf, muscling through all eight of the test networks using a variety of resources. They ranged in scale from 2 AMD Epyc CPUs and 8 Nvidia A100 GPUs to 512 CPUs and 2048 GPUs. Scale clearly mattered. The top range trained AIs in less than a minute while the two-and-eight combination often needed 20 minutes or more.
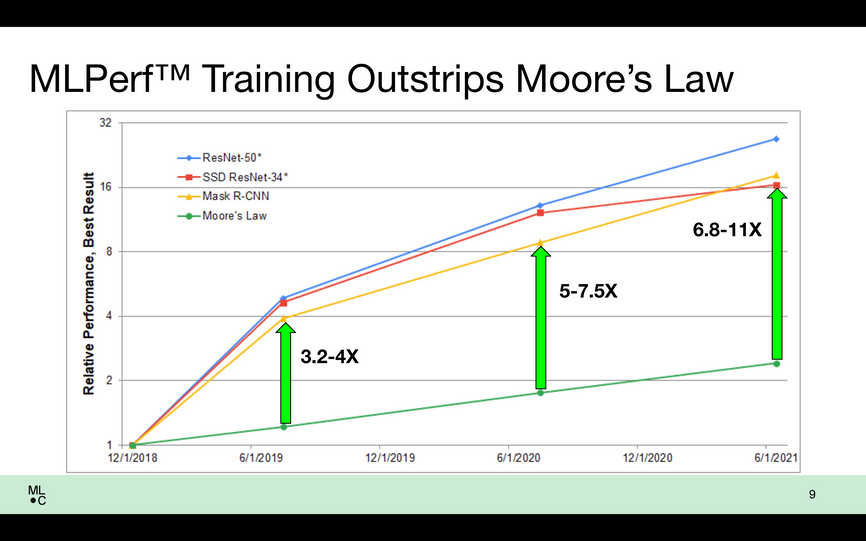
Moore’s Law can only do so much. Software and other progress have made the difference in training AIs.MLCommons
Nvidia worked closely with Microsoft on the benchmark tests, and, as in previous MLPerf lists, Nvidia GPUs were the AI accelerators behind most of the entries, including those from Dell, Inspur, and Supermicro. Nvidia itself topped all the results for commercially available systems, relying on the unmatched scale of its Selene AI supercomputer. Selene is made up of commercially available modular DGX SuperPod systems. In its most massive effort, Selene brought to bear 1080 AMD Epyc CPUs and 4320 A100 GPUs to train the natural language processor BERT in less than 16 seconds, a feat that took most smaller systems about 20 minutes.
According to Nvidia the performance of systems using A100 GPUs has increased more than 5-fold in the last 18 months and 20-fold since the first MLPerf benchmarks three years ago. That’s thanks to software innovation and improved networks, the company says. (For more, see Nvidia’s blog.)
Given Nvidia’s pedigree and performance on these AI benchmarks, its natural for new competitors to compare themselves to it. That’s what UK-based Graphcore is doing when it notes that it’s base computing unit the Pod16—1 CPU and 16 IPU accelerators—beats the Nvidia base unit the DGX A100—2 CPUs and 8 GPUs—by nearly a minute.

Graphcore brought its bigger systems out to play.Graphcore
For this edition of MLPerf, Graphcore debuted image classification and natual language processing benchmarks for its combinations of those base units, the Pod64, Pod128, and (you saw this coming, right?) Pod256. The latter, made up of 32 CPUs and 256 IPUs, was the fourth fastest system behind Nvidia’s Selene and Intel’s Habana Gaudi to finish ResNet image classification training in 3:48. For natural language processing the Pod256 and Pod128 were third and fourth on the list, again behind Selene, finishing in 6:54 and 10:36. (For more see Graphcore’s blog.)
You might have noticed that the CPU-to-accelerator chip ratios are quite different between Nvidia-based offerings—about 1 to 4—and Graphcore’s systems—as low as 1 to 32. That’s by design, say Graphcore engineers. The IPU is designed to depend less on a CPU’s control when operating neural networks.
You can see the opposite with Habana Labs, which Intel purchased for about US $2 billion in 2019. For example, for its high-ranking training on image classification, Intel used 64 Xeon CPUs and 128 Habana Gaudi accelerators to train ResNet in less than 5:30. It used 32 CPUs and 64 accelerators to train the BERT natural language neural net in 11:52. (For more, see Habana’s blog.) [READ MORE]