
Nvidia’s Next GPU Shows That Transformers Are Transforming AI
Transformers, the type of neural network behind OpenAI’s GPT-3 and other big natural-language processors, are quickly becoming some of the most important in industry, and they are likely to spread to other—perhaps all—areas of AI. Nvidia’s new Hopper H100 is proof that the leading maker of chips for accelerating AI is a believer. Among the many architectural changes that distinguish the H100 from its predecessor, the A100, is a “transformer engine.” Not a distinct part of the new hardware exactly, it’s a way of dynamically changing the precision of the calculations in the cores to speed up the training of transformer neural networks.
“One of the big trends in AI is the emergence of transformers,” says Dave Salvator, senior product manager for AI inference and cloud at Nvidia. Transformers quickly took over language AI, because their networks pay “attention” to multiple sentences, enabling them to grasp context and antecedents. (The T in the benchmark language model BERT stands for “transformer” as it does in the occasionally insulting GPT-3.)
But more recently, researchers have been seeing an advantage to applying that same sense of attention to vision and other models dominated by convolutional neural networks. Salvator notes that more than two-thirds of papers about neural networks in the last two years dealt with transformers or their derivatives. “The number of challenges transformers can take on continues to grow,” he says.
However, transformers are among the biggest neural-network models in terms of the number of parameters involved. And they are growing much faster than other models. “We are trending very quickly toward trillion-parameter models,” says Salvator. Nvidia’s analysis shows the training needs of transformer models growing 275-fold every two years, while the trend for all other models is 8-fold growth every two years. Bigger models need more computational resources especially for training, but also for operating in real time as they often need to do. Nvidia developed the transformer engine to help keep up.
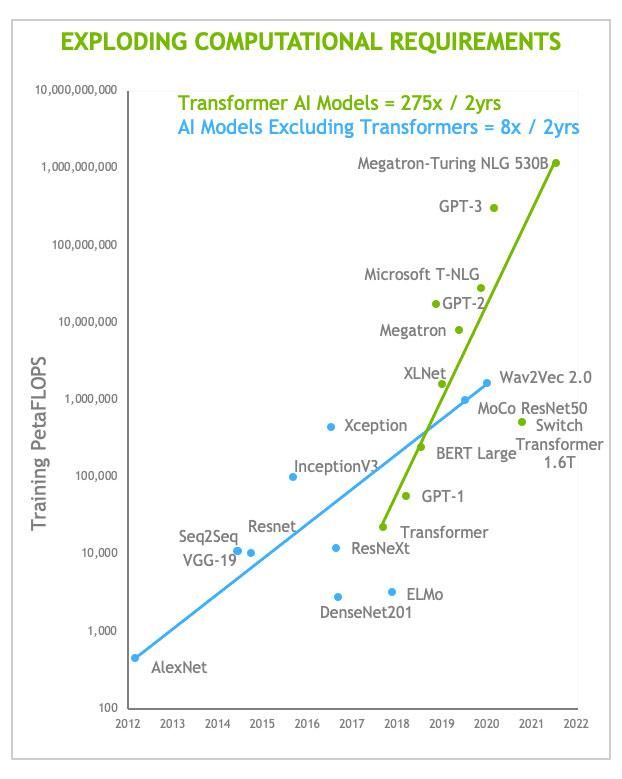
The computational needs of transformers are growing more rapidly than those of other forms of AI. Those are growing really fast, too, of course.NVIDIA
The transformer engine is really software combined with new hardware capabilities in Hopper’s tensor cores. These are the units dedicated to carrying out machine learning’s bread-and-butter calculation—matrix multiply and accumulate. Hopper has tensor cores capable of computing with floating-point numbers of a variety of precision—from 64-bit down to 8-bit. The A100’s cores were designed for floating-point numbers only as short as 16 bits. But the trend in AI computing has been toward developing neural nets that lean on the lowest precision that will still yield an accurate result. The smaller formats compute faster and more efficiently, and they require less memory and memory bandwidth. The addition of 8-bit floating-point units in the H100 leads to a significant speedup—double the throughput compared to its 16-bit units.
The transformer engine’s secret sauce is its ability to dynamically choose what precision is needed for each layer in the neural network at each step in training a neural network. The least-precise units, the 8-bit floating point, can speed through their computations, but then produce 16-bit or 32-bit sums for the next layer if that’s the precision needed there. The Hopper goes a step further, though. Its 8-bit floating-point units can do their matrix math with either of two forms of 8-bit numbers. [READ MORE]